
Building the Unix Spelling Corrector from Scratch - Part 3


The authors have already identified common misspellings using insert/delete/substitute/reverse operations and provided it in the paper appendix:

For example - this the table for deletion:

I became curious about whether I can find the original dataset and program from which this table was produced. I found the literal tables in digital form in a git repo but couldn’t find the original dataset and the transformation program. So I took a shot and tried contacting Prof. Kenneth Church for more pointers:
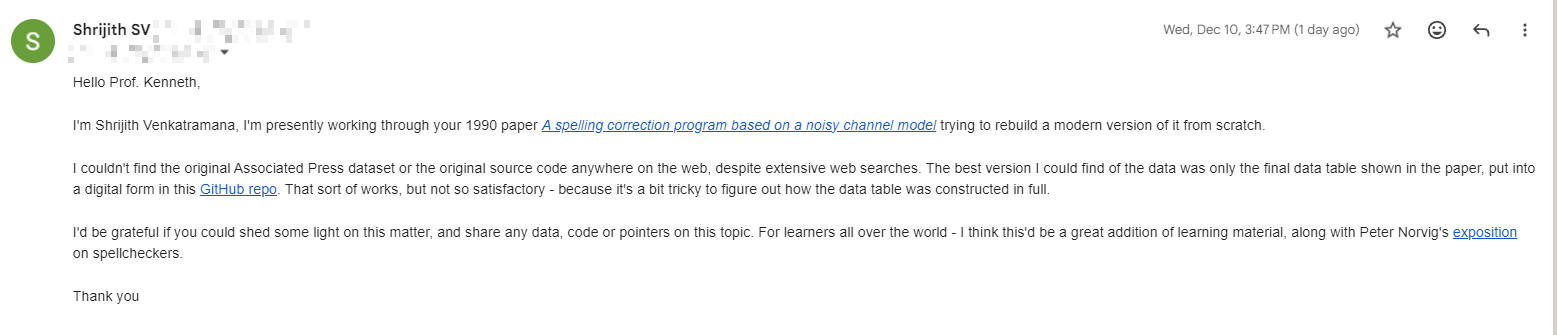
Surprisingly, he got back to me within just a few hours! He is still working hard in the field of NLP, teaching, building startups and so on - you can find more on his website.

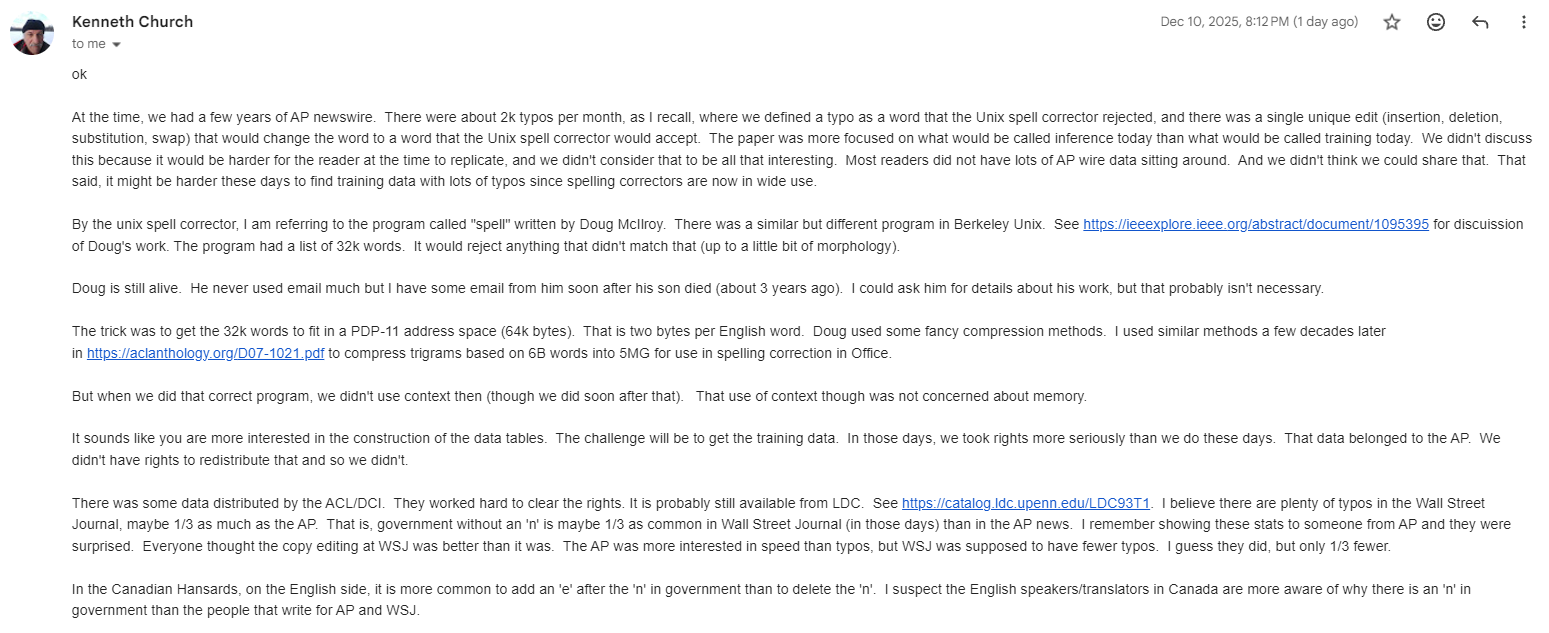
So - from the author himself - we learn that the original dataset is gone - blip! But the table above is sufficient to produce a spell checker. And if we wish to reproduce the data tables ourselves - we can obtain the older WSJ dataset from somewhere and reproduce the data table generator program.
As for me - for now, I’ll go with good professor’s suggestion and just learn to use the data tables they’ve shared, and if there’s sufficient interest later - will dig into the specifics of rebuilding the data tables from scratch.
Also - in the email above - he mentioned Doug McIlroy and other computing luminaries - I strongly recommend checking their contributions and works out. Those in the field of computing must make and to learn from these stalwarts of the field.
Repeating the formula and how to generate useful candidates for correction:

For example, the following is a candidate for the misspelling acress. Clearly we can see - t is inserted at position 2. That is - case 1 below - the “noise” was deletion of the character “t”. So we are looking at “c” following by deletion of “t”.
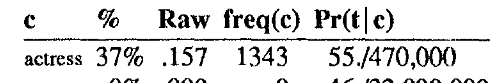
We look up in the appendix - we see this:

This is the formula:

chars[x,y] is simply the amount of times “ct” appears in the corpus. In our case that is 470,000 times - quite believable. So we do 55/470k. Then we get the prior probability of how many times actress appear sin the corpus and the number is this:
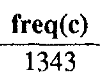
Multiplying these, we get the raw score:

Once we calculate all the raw scores like this for all the candidates, we can do a normalization and get the % score (relative score):
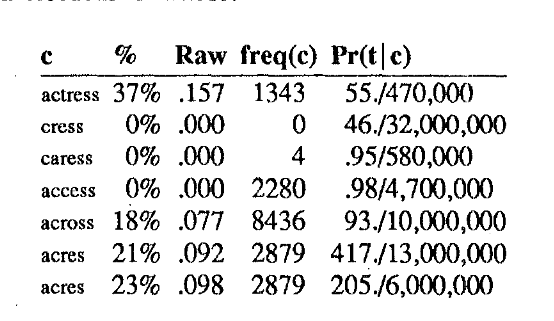
And by sorting by the relative score - we get actress as the best prediction of the lot, standing at 37%.
By the way - the paper doesn’t contain the freq(c ) values - because in the email professor mentioned they had a 500k word list, and they couldn’t open source it:

So clearly - we can’t simply use this dataset, will need to come up with some other way to calculate all these values.
Here are some cases - on how the spell checker works:

The authors come up with a judging method, and it agrees with the majority of the panel of 3 of judges 87% of the times. We can clearly see how dropping prior or the channel/noise leads a noticeable difference in accuracy. For example, Peter Norvig’s original implementation drops the channel input - so it’s actually a weaker implementation than the one described here (conceptually).

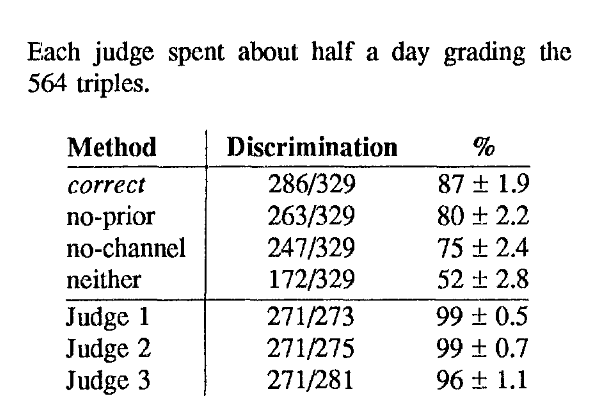
Also, the author hints at showing more context to help with spelling suggestions - that’s where the idea of using trigrams for the purpose (“contextual”) comes from:

Since the prior frequencies and the chars table also not available in this dataset - next I’ll look at Norvig’s implementation as well - and see whether I can get any useful error modeling data there (to speed up my journey).