
How to Write a Spelling Corrector by Norvig - Part 2


Norvig gives a quick refresher of Bayes theorem. But I like the terminology here such as “language model” and “error model” and so on.

The need for two models rather than just sticking to one; it is to reduce the potential of confounding of the variables:

I’m going to skip Norvig’s explanation of the Python code itself, because I think my previous post covers is clearly enough. We will jump to his comments on Evaluation - where we hope to find information how to build the test set, etc.
He looks at Birkbeck spelling corpus, and splits into dev and test sets:

He runs a standard test on this and the results are like this:
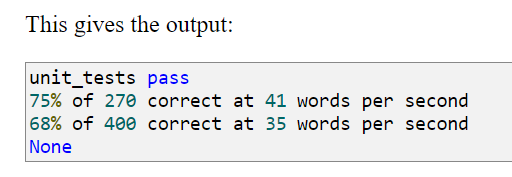
Our Unix correct program on their dataset reported some 87% success rate - wonder how it’d perform on Birkbeck.
One reason for the lower score is small training dictionary, the second reason is inability to deal with suffices, etc more intelligently:

The other problem is that the error model very primitive; it assumes that edit distance 1 is always better than edit distance as a rule:

Another way to improve the model is to use trigrams (surround words as 3 word pairs):

Also, detecting dialect is important to improve accuracy:

Also - the Aspell project has a big test dataset that may come in handy:
So - overall -we got some good pointers from the Norvig article in terms of implementation details:
Potentially better data and test suites
Some useful functions (for producing edit distances)
A more modern comparison point
Points for further exploration
I’ll try to do a more refined implementation combining the original paper’s error model and maybe one of the datasets mentioned by Norvig here (probably the 1st one to see if the correct model does better than the one obtained here).